
由於深度學習的蓬勃發展,近年來在生成圖像上有著許多成功的方法,例如 Autoencoder [2006], Variational Autoencoder (VAE) [2014], GAN [2014], PixelRNN [2016] … 等,而近年來最紅的生成圖像方法就是 diffusion model [1][2][3],也有很多基於 diffusion model 的應用,例如最近很紅的文字生成圖像任務,包含 OpenAI 的多個演化版本:DALL·E [4], GLIDE [5], DALL·E 2 [6] 和 Google Brain 推出的 Imagen [7] 等。


能做出那麼驚人的成果都要歸功於 diffusion model,接著讓我們來一探它的原理吧。
Diffusion model
Diffusion model 的概念就像是 VAE:試圖將原始資料投影到潛在空間上,然後再從潛在空間恢復到原始資料。
它的主要作法是模擬 Markov chain 中的一系列高斯雜訊分佈來逐步地對原始訊號 (影像、音訊) X_0 添加高斯雜訊,進而生成一個服從高斯分佈的訊號 X_T,接著訓練一個學習模型能夠將 X_T 逐步地還原成 X_0。其運算過程共包含兩個步驟,如 圖一 所示:
- 從訊號逐步地添加高斯雜訊 (X_0 ➞ … ➞ X_t-1 ➞ X_t ➞ … ➞ X_T) 的擴散過程 (diffusion process): q(X)
- 從雜訊逐步地還原成訊號 (X_T ➞ … ➞ X_t ➞ X_t-1 ➞ … ➞ X_0) 的逆擴散過程 (reverse process): p_θ(X)
這邊的 q(X) 是不可訓練的,而 p_θ(X) 是可以訓練的,訓練完成後就可以得到我們想要的學習模型。

Diffusion process (擴散過程)
擴散過程採用固定的 Markov chain 形式,即當前的任何狀態都與過去狀態完全無關,即可逐步地向圖片添加高斯雜訊,給定初始資料分佈 X_0 ~ q(X),可以不斷的向分佈中添加高斯雜訊,這個雜訊的變異數為 β_t、均值為 β_t 和當前 t-1 時刻的資料 X_t-1 決定的,這個 β_t 是逐漸增加並且介於 0 和 1 之間,隨著雜訊不斷的添加,最終生成資料 X_T。


Reverse process (逆擴散過程)
逆擴散過程是想要從高斯雜訊中恢復成原始資料,它仍然是一個 Markov chain,我們可以假設它也是一個高斯分佈,所以模型 p_θ 的目標就是要要學習這個高斯分佈的均值和變異數,進而透過連乘來從 X_T 還原成 X_0。


Algorithm

1. Training
在訓練模型的過程中,要對 loss 進行梯度下降,而 loss 經由一系列推導簡化後,最終可以得到 L_simple(θ):
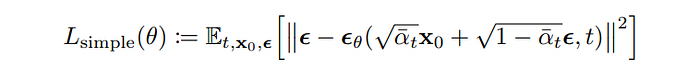
其中 ε 是高斯雜訊,此訓練目標即希望預測的雜訊和真實的雜訊一致,也就是計算兩個雜訊之間的 l2 loss。
2. Sampling
將雜訊的影像丟進模型中,然後持續讓影像變得清晰,就完成 sampling 了,其中用於生成的式子如下:
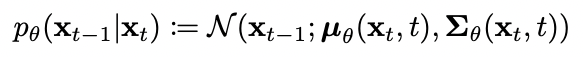
經由數學推導可以得到均值:
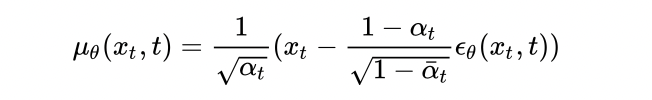
最後就可以得到上一個時刻的生成式了:
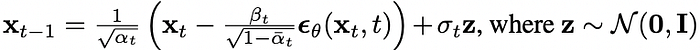
如果對程式操作有興趣的話可以參考以下 Colab 連結:
AIAIART Lesson #7 — Diffusion Models
更多基於 diffusion model 的應用
Super Resolution [8]

Segmentation [9]
使用網路 F 對輸入影像 X_t 進行特徵提取,再用網路 G 對原始影像 I 提取 feature map,兩者相加後再經由 U-net 網路 E, D 得到細化估計的輸出。
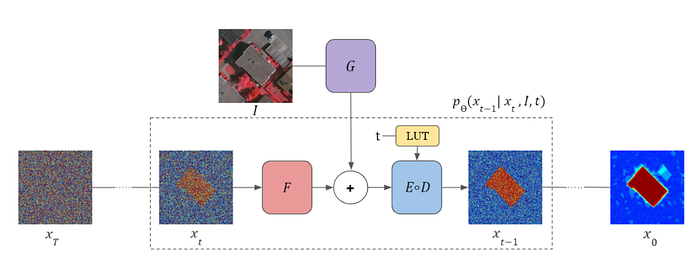
Image2Image Translation [10]



Reference
[1] Deep Unsupervised Learning using Nonequilibrium Thermodynamics (Sohl-Dickstein et al., 2015) [Paper]
[2] Denoising Diffusion Probabilistic Model (DDPM) (Ho et al., 2020) [Paper] [Blog]
[3] Diffusion Models Beat GANs on Image Synthesis (Dhariwal et al., 2021) [Paper]
[4] DALL·E: Zero Shot Text-to-Image Generation (Ramesh et al., 2021) [Paper] [Blog]
[5] GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models (Nichol et al. 2021) [Paper]
[6] DALL·E 2: Hierarchical Text-Conditional Image Generation with CLIP Latents (Ramesh et al., 2022) [Paper] [Blog]
[7] Imagen: Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (Saharia et al., 2022) [Paper] [Blog]
[8] Image Super-Resolution via Iterative Refinement (Saharia et al., 2021) [Paper]
[9] SegDiff: Image Segmentation with Diffusion Probabilistic Models (Amit et al., 2021) [Paper]
[10] SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations (Meng et al., 2021) [Paper]
